
Google Drive has been using OCR (optical character recognition) technology to allow scanned documents uploaded to the cloud storage service to be edited and indexed. Google on Wednesday expanded the OCR capabilities within Google Drive by adding support for over 200 languages.
Google stressed that the reason to expand the OCR capabilities is that most of the information in the world is still stored in physical forms (books, newspapers, and magazines among others) and not digital. For the uninitiated, optical character recognition converts a digital image with text into digital documents using computer algorithms. Images can be processed in (.jpg, .png, and .gif) files or in PDF documents.
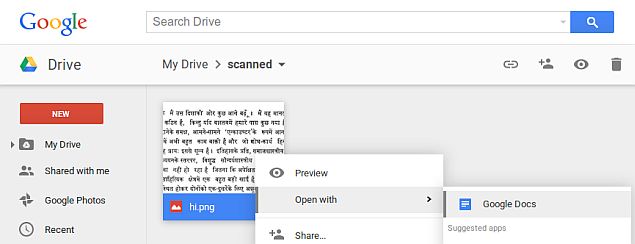
Users can start using the OCR capabilities in Drive by uploading scanned document in PDF or image form after which they can right-click on the document in Drive to open with Google Docs. After choosing the option, a document with the original image alongside extracted text opens, which can be edited. Google notes that users will not be required to specify the language of the document as the OCR in Drive will automatically determine it. The OCR capability in Google Drive is also available in Drive for Android.
The company has also listed some limitations of the OCR technology, stating it will work best on cleanly scanned, high-resolution documents. While has claimed that it is still working to improve performance on poor quality scans and challenging text layouts. The company also lists that OCR will take longer than other uploads in Drive.
Google details how it’s OCR technology works within Drive, “To make this possible, engineering teams across Google pursued an approach to OCR focused on broad language coverage, with a goal of designing an architecture that could potentially work with all existing languages and writing systems. We do this in part by using Hidden Markov Models (HMMs) to make sense of the input as a whole sequence, rather than first trying to break it apart into pieces. This is similar to how modern speech recognition systems recognise audio input.
[“source-gadgets.ndtv.com”]










